{stats/base裡面的基礎操作}
數據匯總:
aggregate(iris[1:4],list(iris$Species),mean)
把dataframe按某種分類方式分開:
pieces <- split(iris,list(iris$Species))
do.call函數:
> result
$setosa
(Intercept) Petal.Width
1.3275634 0.5464903
$versicolor
(Intercept) Petal.Width
1.781275 1.869325
$virginica
(Intercept) Petal.Width
4.2406526 0.6472593
> do.call('rbind',result)
(Intercept) Petal.Width
setosa 1.327563 0.5464903
versicolor 1.781275 1.8693247
virginica 4.240653 0.6472593
subset
baby_names_2008 <- subset(baby_names, year == 2008)
dplyr
數據篩選:
filter(flights, month == 1, day == 1)
filter(flights, month == 1 | month == 2)
filter(flights, month > 6)
Thefilter()function can be used similarly tosubset()to select a set of rows from an original data.frame according to some conditioning statement. As withsubset(),filter()returns an object that maintains a list of the original levels whether those levels exist in the new data.frame or not. Usedroplevels()to restrict the levels to only those that exist in the data.frame. The example below finds just the males from the original data.frame.
| 12 | male <-filter(RuffeSLRH92,sex=="male")xtabs(~sex,data=male) |
|---|---|
## sex
## female male unknown
## 0 201 0
| 12 | male <-droplevels(male)xtabs(~sex,data=male) |
|---|---|
## sex
## male
## 201
數據排序:
arrange(flights, year, month, day)
倒序:
arrange(flights, desc(arr_delay))
數據選擇:
select(flights, year, month, day)
利用distinct()函数根据某列的数值对重复行进行筛选:
distinct(select(flights, origin, dest))
用已有的數據生成新變量:
mutate(flights,gain = arr_delay - dep_delay, speed = distance/air_time * 60)
直接修改已經生成的行列:
transform(flights,
gain = arr_delay - delay,
gain_per_hour = gain / (air_time / 60)
)
只想保留新生成的行列(变量):
transmute(flights,
gain = arr_delay - dep_delay,
gain_per_hour = gain / (air_time / 60)
)
對qualitative數據匯總計數
by_tailnum <- group_by(flights, tailnum)
变量重命名 rename()
rename(tbl_mtcars,mpg1=mpg)
数据关联 join()
inner_join(x = data1, y = data2, by = 'var1')
缺失值代替
data <- replace_na(data = data, replace = list(num = num_mean, type = type_mode))
其他技巧
n(x) #x中行的数量
n_distinct(x): #x中不重复行的数量
first(x), last(x) #x中第一行与最后一行
reshape2
寬數據:
# ozone wind temp
# 1 23.62 11.623 65.55
# 2 29.44 10.267 79.10
# 3 59.12 8.942 83.90
# 4 59.96 8.794 83.97
長數據:
# 1 ozone 23.615
# 2 ozone 29.444
# 3 wind 11.623
# 4 wind 10.267
# 5 temp 65.548
# 6 temp 79.100
melt (由寬數據得到長數據)
pview.type2=melt(pview.type1,variable.name = "type",value.name = "pageview",id.vars = "date")
dcast (由長數據得到寬數據)
数据转换目的:在一行上展示所有Month和Day组合下的Ozone、Solar.R、Wind和Temp值
> data3
<- dcast(data2,Month + Day ~ variable)
>
head(data3)
Month Day Ozone Solar.R Wind Temp
1 5 1 41 190 7.4 67
2 5 2 36 118 8.0 72
3 5 3 12 149 12.6 74
4 5 4 18 313 11.5 62
5 5 5 NA NA 14.3 56
6 5 6 28 NA 14.9 66
find_null
<
- function(x){
return(sum(is.na(x)))}
>
data5
<
- dcast(data2,Month~variable,find_null)
或者对于每个月,求平均数:
head(dcast(aqm, month ~ variable, mean, margins = c("month", "variable")))
month ozone solar.r wind temp (all)
1 5 23.61538 181.2963 11.622581 65.54839 68.70696
2 6 29.44444 190.1667 10.266667 79.10000 87.38384
3 7 59.11538 216.4839 8.941935 83.90323 93.49748
4 8 59.96154 171.8571 8.793548 83.96774 79.71207
5 9 31.44828 167.4333 10.180000 76.90000 71.82689
6 (all) 42.12931 185.9315 9.957516 77.88235 80.05722
plyr
使用plyr包可以针对不同的数据类型,在一个函数内同时完成split – apply – combine三个步骤。
例子:
我们希望用神经网络包来为不同的花进行分类,使用BP神经网络需要的一个参数就是隐藏层神经元的个数。我们来尝试用1到10这十个参数运行模型十次,并观察十个建模结果的预测准确率。但我们并不需要手动运行十次。而是使用mdply函数来完成这个任务。
mlply: Call function with arguments in array or data frame, returning a list.
library(plyr)
library(nnet)
# 确定建模函数
nnet.m <- function(...) {
nnet(Species~.,data=iris,trace=F,...)
}
# 确定输入参数
opts <- data.frame(size=1:10,maxiter=50)
# 建立预测准确率的函数
accuracy <- function(mod,true) {
pred <- factor(predict(mod,type='class'),levels=levels(true))
tb <- table(pred,true)
sum(diag(tb))/sum(tb)
}
# 用mlply函数建立包括10个元素的列表,每个元素包括了一个建模结果
models <- mlply(opts,nnet.m)
# 再用ldply函数读取列表,计算后得到最终结果
ldply(models,'accuracy',true=iris$Species)
size maxiter accuracy
1 1 50 0.5333333
2 2 50 0.9933333
3 3 50 0.6733333
4 4 50 0.9933333
5 5 50 0.9933333
6 6 50 0.9933333
7 7 50 0.9933333
8 8 50 0.9933333
9 9 50 0.9866667
10 10 50 0.9933333
得到baby_names這個數據集中,1880 ~ 2008这129年间,每年的记录数
ddply(.data, .variables, .fun = NULL, ..., .progress = "none",.inform = FALSE,
.drop = TRUE, .parallel = FALSE, .paropts = NULL)
各部分解释如下
- 第一个参数是要操作的原始数据集,比如
baby_name - 第二个参数是按照某个(也可以几个)变量,对数据集分割,比如按照
year对数据集分割,可以写成.(year)的形式 - 第三个参数是具体执行操作的函数,对分割后的每一个子数据集,调用该函数
- 第四个参数可选,表示第三个参数对应函数所需的额外参数
将baby_names按年份写到不同的csv文件中:
d_ply(baby_names, .(year),
function(baby) write.csv(baby, paste0(baby$year[1], ".csv"), row.names = FALSE)
)
读入多个文件中的数据,并合并
可以继续使用上述使用的baby_names数据集,使用如下命令, 将baby_names按年份写到不同的csv文件中。
files <- list.files(pattern = "^\\d+\\.csv")
baby_names_recovered <- ldply(files, read.csv, stringsAsFactors = FALSE
上述命令将129个文件名存储在files变量中,通过ldply,读取每个文件,并最后通过ldply合并成一个data.frame。需要说明的是ldply的第一个参数要求list,但是files变量却是vector,这个没有影响,函数内部会将第一个参数通过as.list()转换成list。
tidyr
gather 宽表变长表
使用gather()函数实现宽表转长表,语法如下:
gather(data, key, value, …, na.rm = FALSE, convert = FALSE)
data:需要被转换的宽形表
key:将原数据框中的所有列赋给一个新变量key
value:将原数据框中的所有值赋给一个新变量value
…:可以指定哪些列聚到同一列中
na.rm:是否删除缺失值
# 除了car列外,其余列聚合成两列,分别命名为attribute和value
mtcarsNew <- mtcars %>% gather(attribute, value, -car)
如果你想gather在map和gear之间的所有列而保持carb和car列不变,可以像下面这样做:
# gather在map和gear之间的所有列,而保持carb和car列不变
mtcarsNew <- mtcars %>% gather(attribute, value, mpg:gear)
不连续筛选
mtcarsNew <- mtcars %>% gather(`gear`,`carb`,key = "attribute", value = "value", -car)
spread 长数据变宽数据
spread(data, key, value, fill = NA, convert = FALSE, drop = TRUE)
data:为需要转换的长形表
key:需要将变量值拓展为字段的变量
value:需要分散的值
fill:对于缺失值,可将fill的值赋值给被转型后的缺失值
mtcarsSpread <- mtcarsNew %>% spread(attribute, value)
unite 多列合并为1列
unite(data, col, …, sep = “_”, remove = TRUE)
data:为数据框
col:被组合的新列名称
…:指定哪些列需要被组合
sep:组合列之间的连接符,默认为下划线
remove:是否删除被组合的列
# 把date,hour,min和second列合并为新列datetime
# R中的日期时间格式为"Year-Month-Day-Hour:Min:Second"
dataNew <- data %>%unite(datehour, date, hour, sep = ' ') %>%unite(datetime, datehour, min, second, sep = ':')
dataNew
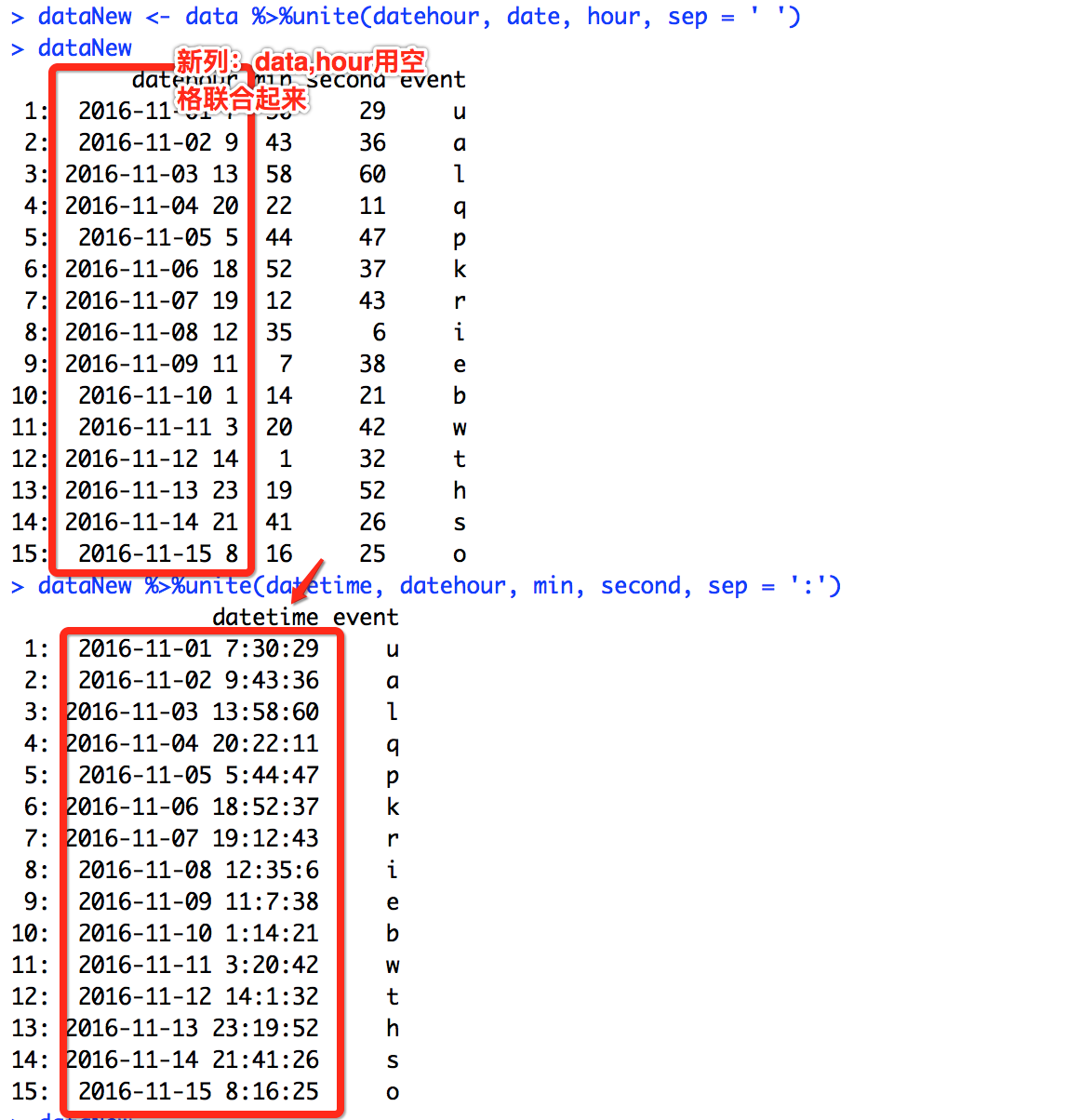
separate 将一列分离为多列
separate(data, col, into, sep = “[^[:alnum:]]+”, remove = TRUE,
convert = FALSE, extra = “warn”, fill = “warn”, …)
data:为数据框
col:需要被拆分的列
into:新建的列名,为字符串向量
sep:被拆分列的分隔符
remove:是否删除被分割的列
# 可以用separate函数将数据恢复到刚创建的时候
# 首先,将datetime分为date列和time列 然后,将time列分为hour,min,second列
data1 <- dataNew %>%separate(datetime, c('date', 'time'), sep = ' ') %>%separate(time, c('hour', 'min', 'second'),
sep = ':')
R語言對缺失值的處理
用中值或平均值代替
x_mean <- mean(df$x, na.rm = TRUE)
x_median <- median(df$x, na.rm = TRUE)
df2 <- replace_na(data = df, replace = list(x = x_mean, y = y_mode))
識別缺失值用的函數
is.na()、is.nan()、和is.infinite()
用mice包中的md.pattern()函数探索缺失值的模式